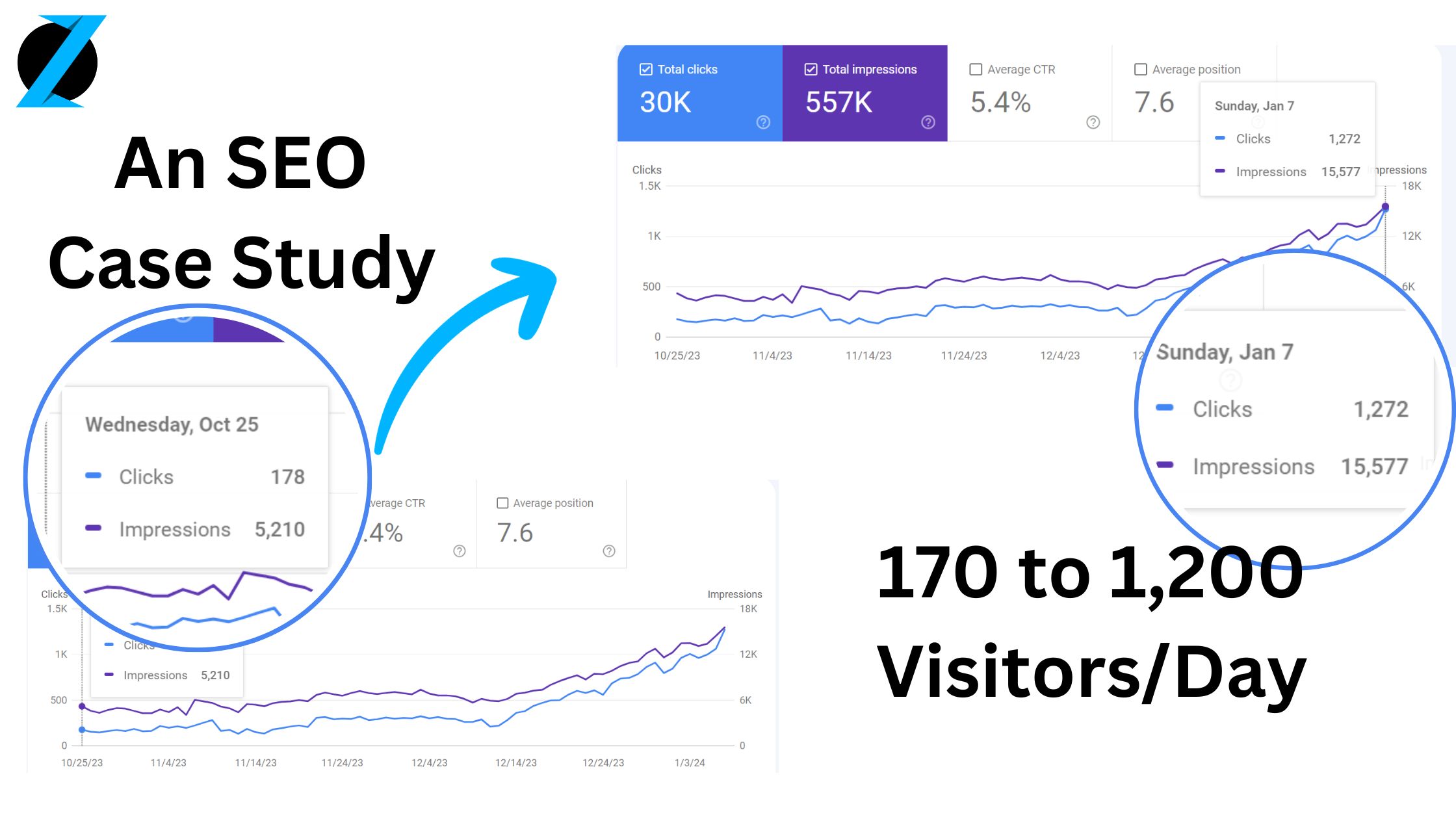
170 to 1,200 Visitors in 85 Days: An SEO Case Study
Categories
Learn how we increased a website’s organic traffic from 170 to 1,200+ visitors per day in 85 days. Our comprehensive SEO strategy involved extensive keyword research, targeted content creation, impactful technical fixes, and a cohesive link building campaign.

