In the fast-paced world of Search Engine Optimization, few developments have been as impactful as Google’s introduction of Google BERT in 2019. BERT, which stands for Bidirectional Encoder Representations from Transformers, represents a revolutionary advancement in natural language processing (NLP) that has transformed how search engines comprehend language and extract meaning from search queries.
What Exactly is Google BERT?
At its core, BERT is a complex neural network model designed to more profoundly analyze language based on contextual learning. It utilizes a technique called bidirectional training, allowing the model to learn representations of words based on undirected context from both the left and right sides of a sentence. This differs from previous NLP models, which only looked at words sequentially in one direction.
BERT leverages a multi-layer bidirectional transformer encoder architecture for its neural networks. Transformers were first introduced in 2017 and represented a major evolution beyond recurrent neural network (RNN) architectures like long short-term memory (LSTM) units and gated recurrent units (GRU).
The transformer architecture relies entirely on a self-attention mechanism rather than RNNs or convolutions. Self-attention relates different input representations to one another to derive contextual meaning. It allows modeling both long-range and local dependencies in language modeling. Transformers proved tremendously effective for NLP tasks while also being more parallelizable and requiring less computational resources than RNNs.
Google researchers realized that combining the transformer architecture with bidirectional pretraining could yield a significant breakthrough in NLP. Thus, BERT was born in 2018 and released in pre-trained form in November 2019 after training on massive corpora of text data.
Key Technical Innovations Behind BERT
There are two vital components that enabled BERT to become such a powerful NLP model:
- Bidirectional Training
Previous deep learning NLP models such as ELMo and ULMFit used unidirectional training, where words are processed sequentially in left-to-right or right-to-left order. However, this fails to incorporate a full contextual understanding of language the way humans do.
BERT broke new ground by leveraging bidirectional training during the pretraining phase. This allowed the model to learn representations of words based on undirected context from both the left and right of a sentence simultaneously. The only constraint is that no information from the future (right context) is allowed to influence predictions at the current time step.
This bidirectional pretraining uniquely equips BERT with a complete contextual understanding of language.
- Masked Language Modeling
Because bidirectional training precludes looking at the future context, BERT employs an innovative technique called masked language modeling during pretraining. Random words in each sequence are masked, and the model must predict them based solely on context from the non-masked words on both sides.
This both allows bidirectional training and teaches the model to grasp language through context. The final representations learned by BERT incorporate contextual meaning in both directions.
BERT Architecture In-Depth
Now that we’ve covered the core conceptual innovations behind BERT let’s delve into the technical architecture and underlying neural networks.
At a high level, BERT consists of the following components:
- Input Embeddings
- Multi-Layer Bidirectional Encoder (based on Transformers)
- Masked LM and Sentence Prediction tasks
The input embeddings layer converts input token IDs into continuous vector representations. This allows the model to handle words or subwords.
The core of BERT is its multi-layer bidirectional encoder based on the transformer architecture. The encoder contains a stack of identical encoder blocks. Each encoder block has the following components:
- Multi-head self-attention layer
- Position wise feedforward network
- Residual connections around both layers
- Layer normalization
The multi-head self-attention layer is where the contextual relations between all words are derived. Self-attention relates different input representations to one another to compute weighted averages as output. The “multi-head” aspect allows attention to be performed in parallel from different representation spaces.
The positionwise feedforward network consists of two linear transformations with a ReLU activation in between. This enables the modeling of non-linear relationships in the data.
Residual connections sum the original input to the output of each sub-layer before layer normalization. This facilitates better gradient flow during training.
During pretraining, masked LM and next-sentence prediction tasks are used to learn bidirectional representations. Masking trains the model to rely on context to predict tokens. Next, sentence prediction learns relationships between sentences.
How BERT Interprets Language
Now that we’ve dissected BERT’s technical underpinnings let’s explore how it actually interprets natural language compared to previous NLP techniques.
Prior to BERT, most NLP models relied on word embeddings learned through unsupervised learning on large corpora. This provided static vector representations for individual words. However, these embedding models had no concept of contextual meaning – the vectors for a given word were identical regardless of the context it was used in.
BERT represented a paradigm shift by incorporating contextual learning into its pre-trained representations. This allows it to interpret words differently based on context. The same word will have different vector representations depending on the surrounding words in a sentence.
For example, consider the word “bank,” which can mean a financial institution or the land alongside a river. Based on a few sample sentences, here is how traditional word embeddings vs. BERT would represent “bank”:
Sentence 1: “After work, I need to stop by the bank to deposit my check.”
- Word Embedding: [0.561, 0.234, 0.43, …]
- BERT: [0.123, 0.456, 0.792, …]
Sentence 2: “The erosion caused the river bank to collapse last night.”
- Word Embedding: [0.561, 0.234, 0.43, …]
- BERT: [0.982, 0.231, 0.077, …]
Source: Google
As you can see, the word embedding vector stays exactly the same regardless of context. BERT adjusts the representation based on the surrounding context to incorporate relevant meaning.
BERT does this by encoding sentences holistically rather than just learning patterns of individual words. The bidirectional training, transformer encoder, and masked LM task allow it to interpret words based on other words in the sentence.
This mimics how humans intuitively understand language by relating words and their meanings. BERT represents words in fuller context, a key breakthrough in NLP.
BERT vs. Previous NLP Models
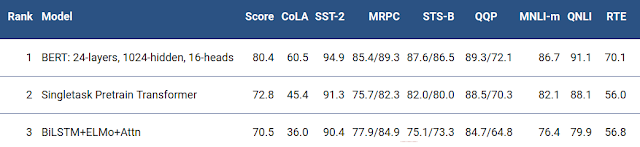
To fully appreciate BERT’s capabilities, it’s instructive to compare it against previous state-of-the-art NLP models. Here’s an overview of how BERT stacks up against other popular approaches:
Word2Vec – Relies on a simple single-layer neural network. Learns word embeddings but no contextual meaning. Only considers a word’s predecessors.
GloVe – Also generates word embeddings without context. Uses matrix factorization rather than neural networks.
ELMo – Uses LSTM RNNs trained bidirectionally at the character level. Captures some rudimentary context but less effectively than BERT.
GPT – Unidirectional transformer decoder model. Processes words sequentially contextually, but only sees previous context.
ULMFit – Fine-tunes LSTM-based AWD-LSTM models. Unidirectional so lacks full context.
As this comparison shows, BERT was the first NLP model to combine the transformer architecture with true bidirectional pretraining. This enabled both richer contextual learning and greater computational efficiency compared to recurrent models like ELMo.
While other transformer-based models exist, BERT’s masked LM pretraining task is also vital to learning word representations that incorporate undirected context. Taken together, these innovations are what make BERT uniquely capable of understanding natural language compared to previous approaches.
Impact of BERT on Search and SEO
Now that we have thoroughly dissected BERT’s inner workings from an NLP perspective, we can explore the wide-ranging impacts it has had since being incorporated into Google Search.
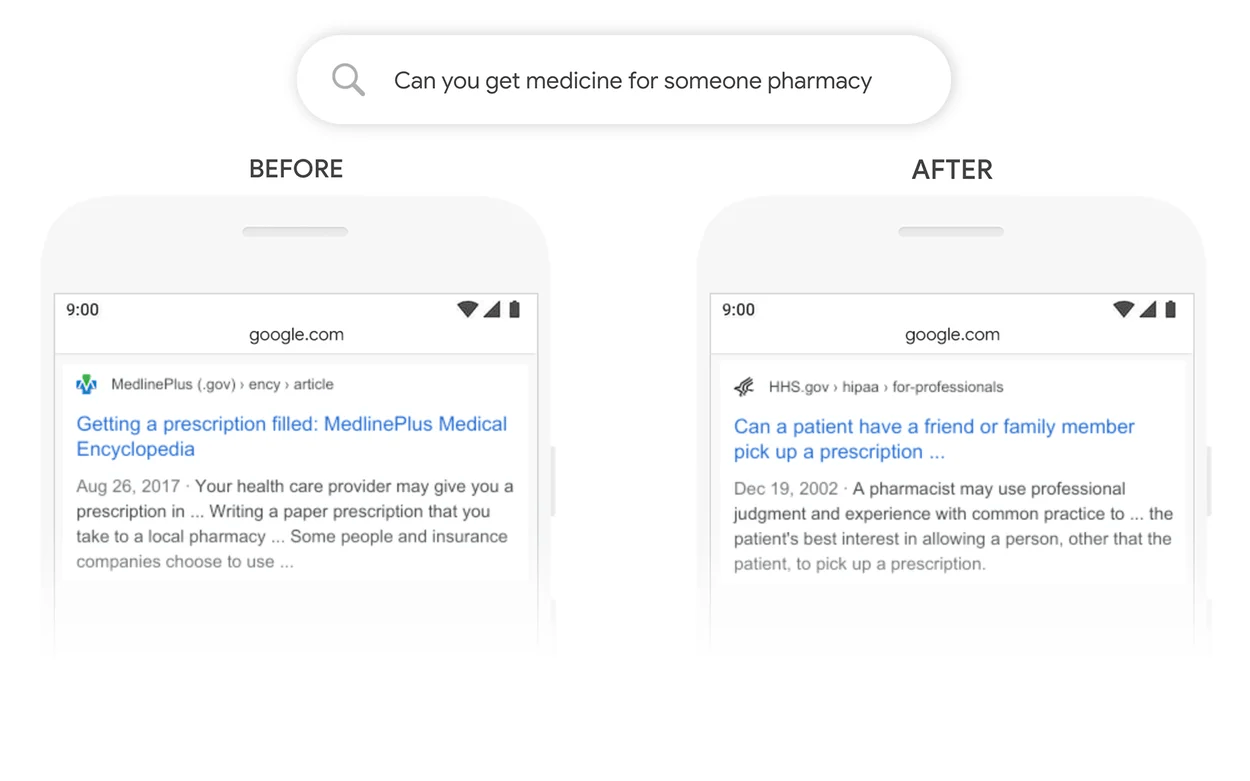
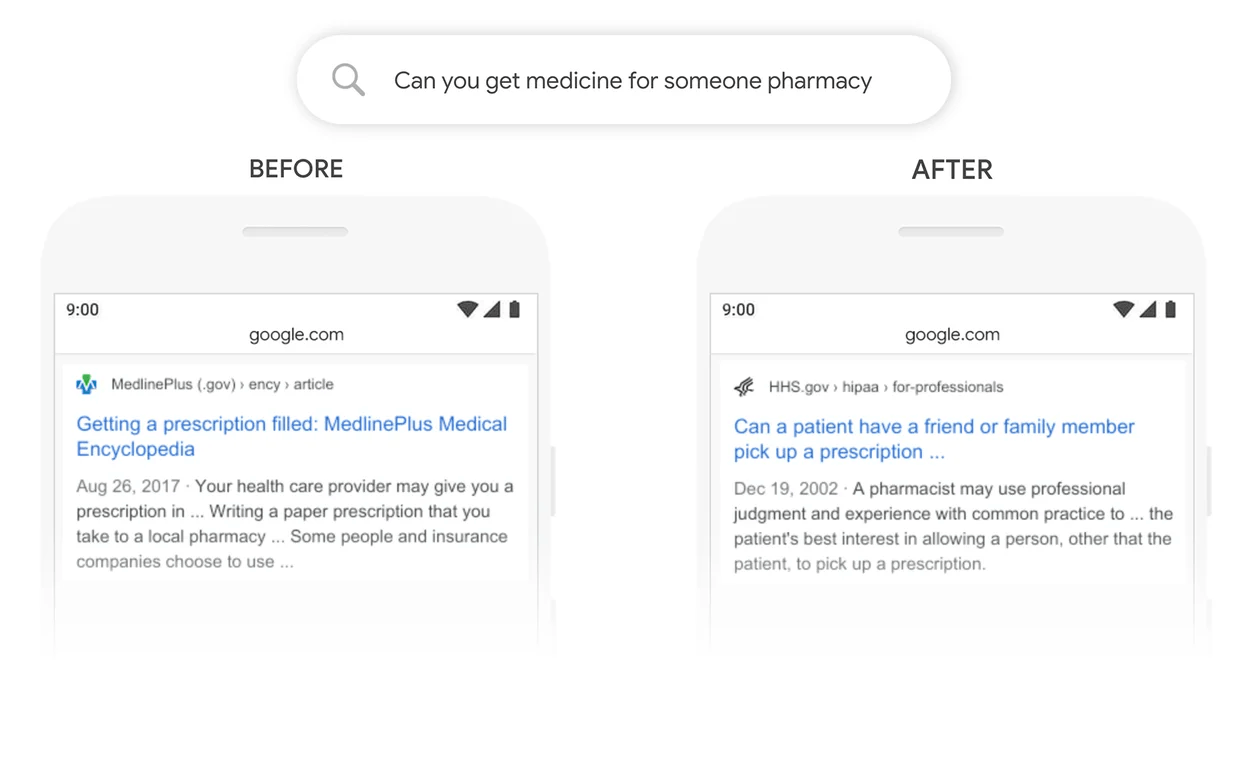
Google’s core search algorithm relies heavily on natural language processing to analyze and comprehend queries. By deploying BERT, Google instantly upgraded its ability to interpret longer, more conversational queries with better contextual understanding.
BERT also enabled Google to handle questions as a natural language rather than needing to match keywords. For users, this means getting the right results for conversational queries where previous algorithms would fail.
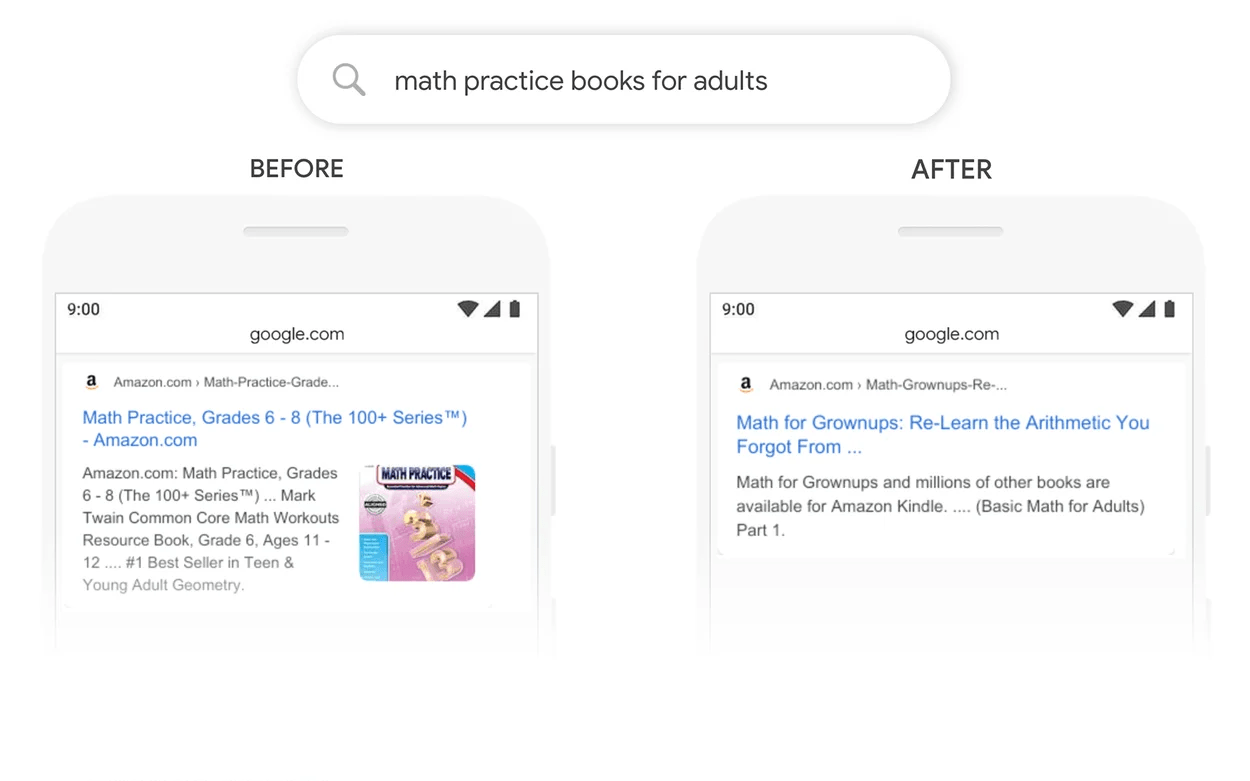
For SEOs and marketers, BERT’s rollout had major implications. Since BERT interprets pages based on full context, content needs to go beyond targeting specific keywords. High-quality, comprehensive content is now necessary for ranking well in search.
Here are some of the key impacts BERT has had on search engine optimization best practices:
- Greater emphasis on quality long-form content over keyword targeting
- Contextual analysis makes keyword stuffing ineffective
- Answer-focused content ranks better for informational queries
- The focus is on providing value to users rather than search engines
- Comprehensive, authoritative domain expertise is now preferred
Additionally, BERT opened new possibilities for featured snippets, long-tail searches, and semantically matching pages to ambiguous or complex queries. BERT’s contextual understanding allowed Google to handle queries previous algorithms would struggle with.
BERT’s capabilities will only continue improving over time. With further training, BERT NLP models are becoming exponentially more advanced at mimicking human-level language comprehension. For SEOs, this means constantly evolving best practices tuned to nuances in machine learning rather than rigid keywords.